Everardo Shain Ruvalcaba
Friday, June 3, 2022
IMDB Sentiment Analysis
Overview
This was a group project focused on the development of a sentiment analysis pipeline for IMDB movie reviews using deep learning–based natural language processing techniques. A Convolutional Neural Network (CNN) was trained to classify reviews as positive or negative, while also generating fixed-length semantic embeddings. It included dataset preprocessing, model training with pretrained word embeddings, and an inference pipeline capable of exporting 300-dimensional feature vectors from raw text inputs.
My main contribution was the implementation of the inference and feature-extraction pipeline, including reading input comments from CSV files, text preprocessing with spaCy, vocabulary-based encoding using the trained tokenizer, feature extraction using the trained CNN model, and structured export of learned embeddings to a CSV output file.
Tools
Environment
- Python: programming language.
- VS Code: programming IDE.
Dependencies
- torch: PyTorch library for tensor operations, model training, and inference.
- torch.nn / torch.nn.functional: Neural network layers, activations, and pooling operations.
- torchtext: Dataset loading, vocabulary construction, and batch iteration for NLP tasks.
- CNN_model: Custom module defining the CNN architecture.
- spaCy: NLP library used for text tokenization.
- en_core_web_sm: spaCy English language model used for tokenization.
- numpy: Numerical operations and array handling.
- pandas: Data organization and CSV export.
- csv: Reading input data and writing vectorized outputs.
- random: Dataset splitting and reproducibility.
- datetime: Execution-time logging.
- os: File and path handling.
- sys: System-level utilities.
- time: Runtime and performance-related utilities.
Dataset
Description
Name: Large Movie Review Dataset v1.0
The core dataset contains 50,000 reviews split evenly into 25k train and 25k test sets. The overall distribution of labels is balanced (25k pos and 25k neg). We also include an additional 50,000 unlabeled documents for unsupervised learning.
In the entire collection, no more than 30 reviews are allowed for any given movie because reviews for the same movie tend to have correlated ratings. Further, the train and test sets contain a disjoint set of movies, so no significant performance is obtained by memorizing movie-unique terms and their associated with observed labels. In the labeled train/test sets, a negative review has a score <= 4 out of 10, and a positive review has a score >= 7 out of 10. Thus reviews with more neutral ratings are not included in the train/test sets. In the unsupervised set, reviews of any rating are included and there are an even number of reviews > 5 and <= 5.
Source and Citation
The dataset was introduced by Maas et al. in Learning Word Vectors for Sentiment Analysis (ACL 2011).
Available: https://www.kaggle.com/datasets/pranayprasad/aclimdb
Reference:
Maas, A. L., Daly, R. E., Pham, P. T., Huang, D., Ng, A. Y., & Potts, C. (2011).
Learning Word Vectors for Sentiment Analysis.
Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics (ACL).
Code
CNN Model
import torch
import torch.nn as nn
import torch.nn.functional as F
class CNN(nn.Module):
def __init__(self, vocab_size, embedding_dim, n_filters, filter_sizes, output_dim, dropout):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.conv_0 = nn.Conv2d(in_channels=1, out_channels=n_filters, kernel_size=(filter_sizes[0],embedding_dim))
self.conv_1 = nn.Conv2d(in_channels=1, out_channels=n_filters, kernel_size=(filter_sizes[1],embedding_dim))
self.conv_2 = nn.Conv2d(in_channels=1, out_channels=n_filters, kernel_size=(filter_sizes[2],embedding_dim))
self.fc = nn.Linear(len(filter_sizes)*n_filters, output_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
x = x.permute(1, 0)
embedded = self.embedding(x)
embedded = embedded.unsqueeze(1)
conved_0 = F.relu(self.conv_0(embedded).squeeze(3))
conved_1 = F.relu(self.conv_1(embedded).squeeze(3))
conved_2 = F.relu(self.conv_2(embedded).squeeze(3))
pooled_0 = F.max_pool1d(conved_0, conved_0.shape[2]).squeeze(2)
pooled_1 = F.max_pool1d(conved_1, conved_1.shape[2]).squeeze(2)
pooled_2 = F.max_pool1d(conved_2, conved_2.shape[2]).squeeze(2)
cat = self.dropout(torch.cat((pooled_0, pooled_1, pooled_2), dim=1))
return self.fc(cat) , cat
CNN Train
import torch
from torchtext import data
from torchtext import datasets
import time, random
from CNN_model import CNN
import torch.nn as nn
import torch.nn.functional as F
from datetime import datetime
SEED = 1234
torch.manual_seed(SEED)
torch.cuda.manual_seed(SEED)
torch.backends.cudnn.deterministic = True
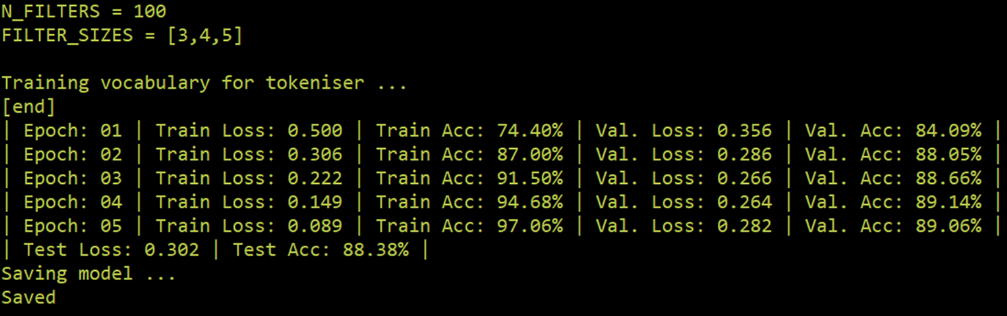
print('Training vocabulary for tokeniser ...')
TEXT = data.Field(tokenize='spacy')
LABEL = data.LabelField(dtype=torch.float)
train_data, test_data = datasets.IMDB.splits(TEXT, LABEL)
train_data, valid_data = train_data.split(random_state=random.seed(SEED))
TEXT.build_vocab(train_data, max_size=25000, vectors="glove.6B.100d")
LABEL.build_vocab(train_data)
print('[end]')
BATCH_SIZE = 64
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
train_iterator, valid_iterator, test_iterator = data.BucketIterator.splits(
(train_data, valid_data, test_data),
batch_size=BATCH_SIZE,
device=device)
INPUT_DIM = len(TEXT.vocab)
EMBEDDING_DIM = 100
N_FILTERS = 100
FILTER_SIZES = [3,4,5]
OUTPUT_DIM = 1
DROPOUT = 0.5
model = CNN(INPUT_DIM, EMBEDDING_DIM, N_FILTERS, FILTER_SIZES, OUTPUT_DIM, DROPOUT)
pretrained_embeddings = TEXT.vocab.vectors
model.embedding.weight.data.copy_(pretrained_embeddings)
import torch.optim as optim
optimizer = optim.Adam(model.parameters())
criterion = nn.BCEWithLogitsLoss()
model = model.to(device)
criterion = criterion.to(device)
def binary_accuracy(preds, y):
"""
Returns accuracy per batch, i.e. if you get 8/10 right, this returns 0.8, NOT 8
"""
#round predictions to the closest integer
rounded_preds = torch.round(torch.sigmoid(preds))
correct = (rounded_preds == y).float() #convert into float for division
acc = correct.sum()/len(correct)
return acc
def train(model, iterator, optimizer, criterion):
epoch_loss = 0
epoch_acc = 0
model.train()
for batch in iterator:
optimizer.zero_grad()
predictions , __ = model(batch.text)
predictions = predictions.squeeze(1)
loss = criterion(predictions, batch.label)
acc = binary_accuracy(predictions, batch.label)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
epoch_acc += acc.item()
return epoch_loss / len(iterator), epoch_acc / len(iterator)
def evaluate(model, iterator, criterion):
epoch_loss = 0
epoch_acc = 0
model.eval()
with torch.no_grad():
for batch in iterator:
predictions, __ = model(batch.text)
predictions = predictions.squeeze(1)
loss = criterion(predictions, batch.label)
acc = binary_accuracy(predictions, batch.label)
epoch_loss += loss.item()
epoch_acc += acc.item()
return epoch_loss / len(iterator), epoch_acc / len(iterator)
N_EPOCHS = 5 # more >> overfitting
for epoch in range(N_EPOCHS):
train_loss, train_acc = train(model, train_iterator, optimizer, criterion)
valid_loss, valid_acc = evaluate(model, valid_iterator, criterion)
print(f'| Epoch: {epoch+1:02} | Train Loss: {train_loss:.3f} | Train Acc: {train_acc*100:.2f}% | Val. Loss: {valid_loss:.3f} | Val. Acc: {valid_acc*100:.2f}% |')
test_loss, test_acc = evaluate(model, test_iterator, criterion)
print(f'| Test Loss: {test_loss:.3f} | Test Acc: {test_acc*100:.2f}% |')
mFile = datetime.now().strftime('%Y-%m-%d-%H-%M-%S');
print('Saving model ...')
torch.save(model, './MODELS/' + mFile + '.pth')
torch.save(TEXT, './MODELS/' + mFile + 'TEXT')
print('Saved')
Pipeline
import torch
from torchtext import data
from torchtext import datasets
import time, random
from CNN_model import CNN
import torch.nn as nn
import torch.nn.functional as F
from datetime import datetime
import os
import spacy
import sys
import numpy as np
from os import listdir
from os.path import isfile, join
from csv import reader
import pandas
import csv
import numpy
nlp = spacy.load('en_core_web_sm')
def predict_sentiment(sentence, min_len=5):
tokenized = [tok.text for tok in nlp.tokenizer(sentence)]
if len(tokenized) < min_len:
tokenized += ['<pad>'] * (min_len - len(tokenized))
indexed = [TEXT.vocab.stoi[t] for t in tokenized]
tensor = torch.LongTensor(indexed).to(device)
tensor = tensor.unsqueeze(1)
prediction, FC = model(tensor);
prediction = torch.sigmoid(prediction)
return prediction.item(), FC
ModelFile = 'Mymodel';
VectorizerFile = 'Myvectorizer';
OutputFile = 'vectorizacion.csv';
InputFile = 'comments.csv';
file = open(InputFile);
h= len(list(csv.reader(file)));
w=301;
M = [[0 for x in range(w)] for y in range(h)]
H = [0 for x in range(w)]
H[0]="Comment";
for x in range(w-1):
H[x+1]="V%d" % x;
print('## << Testing CNN >>\n')
print('* Test date and time : ' + datetime.now().strftime('%Y-%m-%d %H:%M:%S'))
print('* Using model: ' + ModelFile + '.ptn')
print('* Input file: ' + InputFile)
# Load model
model = torch.load('./MODELS/' + ModelFile + '.pth');
TEXT = torch.load('./MODELS/' + VectorizerFile );
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = model.to(device);
# open file in read mode
with open(InputFile, 'r') as read_obj:
csv_reader = reader(read_obj)
i=0;
for rows in csv_reader:
comment=rows[0];
__, y = predict_sentiment(comment);
y = y.cpu();
y = y.detach().numpy();
M[i][0]=comment;
for j in range(300):
M[i][j+1]=y[0][j];
i=i+1;
df=pandas.DataFrame(M);
df.to_csv(OutputFile,index=False, header = H)
print('[end]')
Gallery